](https://thepabloaguilar.dev/pt-br/monkey-patching-nao-e-tao-ruim/cover.jpeg)
Contexto
Há alguns meses atrás comecei a contribuir em biblioteca Open Source para python, returns, ela têm vários recursos e contêineres legais para nos ajudar de diferentes maneiras. Não irei me aprofundar neles nesse post, mas você pode acessar a documentação para saber mais sobre!
Nesse post irei falar sobre o porquê nós escolhemos a técnica de monkey patching para implementar uma de nossas features onde o objetivo era melhorar a rastreabilidade de falhas para os contêineres Result.
Uma breve explicação sobre o que é o Result, basicamente, seu código pode ter dois caminhos:
- Sucesso, seu código executou normalmente sem nenhum erro
- Falha, seu código falhou por alguma razão, por exemplo, uma quebra de regra de negócio ou uma exceção foi lançada
O contêiner abstrai esses possíveis caminhos para nós, veja o exemplo abaixo:
from returns.result import Failure, Result, Success
def eh_par(numero: int) -> Result[int, int]:
if arg % 2 == 0:
return Success(numero)
return Failure(numero)
assert eh_par(2) == Success(2)
assert eh_par(1) == Failure(1)
Usar o Result pode ser uma boa ideia porque você não precisa mais lidar com exceções (négocio, sistema) lançadas
e sair colocando try...except em todo lugar do seu código, você precisa apenas retornar um contêiner Failure.
Rastreabilidade de Falhas: explicação da feature
Failure é bom, mas exceções normais nos dão algo importante: onde elas foram lançadas.
Inspirado na feature de rastreamento de falhas do dry-rb, que é uma coleção de bibliotecas para Ruby, nós começamos as discussões para oferecer essa opção para os usuários da returns. Uma coisa muito importante foi considerada para fazer a implementação, que os usuários que não fossem utilizar a feature não poderiam ter a performance dos seus sistemas/aplicações afetada!
A forma simples, fácil e única (eu acho) para implementar a feature é pegarmos a pilha de chamadas e fazer algumas manipulações com ela. Em Python é bem simples fazermos isso, porém é uma operação bem custosa que pode afetar a performance se for feita muitas vezes. Abaixo você consegue ver as métricas extraídas sobre o consumo de memória quando criamos um contêiner Failure pegando e não pegando a pilha de chamadas, respectivamente:
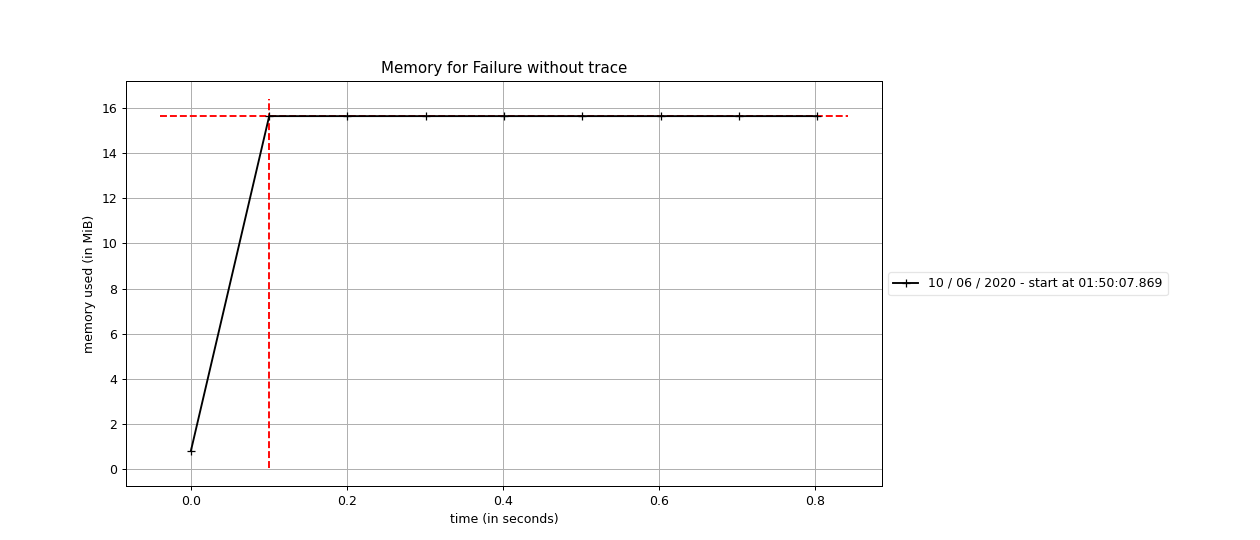
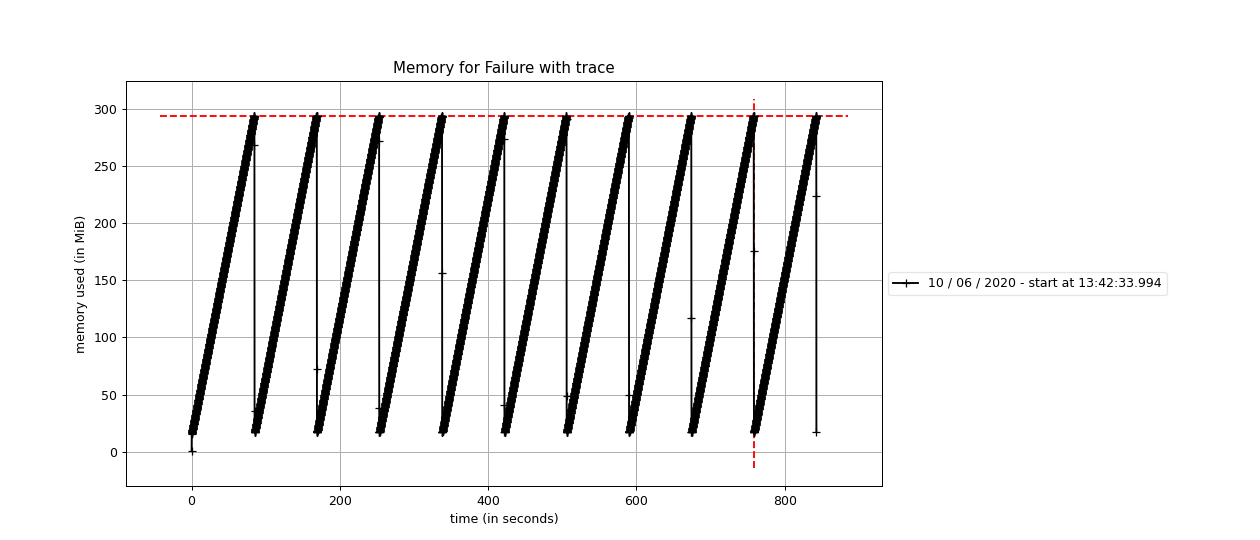
Como nós podemos implementar a feature de rastreamento?
Nós já sabemos que o rastreamento deve ser opcional, dado que usuários que não irão utiliza-lo não podem ser afetados, e como vimos nas imagems acima, quando ativamos o rastreamento (pegando a pilha de chamadas) tivemos um consumo grande de memória comparada sem o rastreamento!
Para tornar o rastremento opcional tinhamos duas opções:
- Usar uma variável de ambiente
- Usar monkey patching
Pelo título desse post você já deve saber que escolhemos a segunda opção.
Por que monkey patching?
Monkey Patching é a abordagem mais sofisticada e elegante do que utilizar uma variável de ambiente, nós podemos separar de maneira correta a código da feature de rastreamento da classe que queremos que seja rastreável e não dependemos de nenhum recurso externo. Usando uma variável de ambiente acabaríamos com algo similar ao exemplo abaixo em nossas classes, nós podemos desacoplar a estrutura do if da classe porém em algum outro lugar do nosso código esse if estaria lá:
import os
class Exemplo:
def __init__(self) -> None:
if os.getenv('RETURNS_TRACE'):
self._tracking = []
Monkey patching é um amigo conhecido dos programadores Python, nós usamos muito enquanto escrevemos testes para fazermos mocks de tudo que queremos (requests para API, interações com o banco de dados e etc.), porém não é muito utilizado em códigos de “produção” porque temos algumas desvantagens, como por exemplo, ele não é Thread Safe e pode criar vários bugs dado que ele afeta o código base inteiro em runtime. Mas nós entendemos que a feature de rastreamento é para propósitos de desenvolvimento, nós não nos importamos com o problema de thread safety e sabemos exatamente onde iremos usar o monkey patching!
Podemos ter um monkey patching que seja thread safe em Python?
Sim, podemos. Mas isso é um assunto para outro artigo.
Depois de algumas discussões, nós finalmente entregamos nossa feature de rastreamento de falhas, e agora nossos usuários podem ativar explicitamente em seus códigos o rastreamento para os contêineres Result.
from returns.result import Failure, Result
from returns.primitives.tracing import collect_traces
@collect_traces
def retorna_falha(argumento: str) -> Result[str, str]:
return Failure(argumento)
failure = retorna_falha('example')
for trace_line in failure.trace:
print(f"{trace_line.filename}:{trace_line.lineno} in `{trace_line.function}`")
A saída será algo como:
/returns/returns/result.py:529 in `Failure`
/exemplo_folder/exemplo.py:5 in `retorna_falha`
/exemplo_folder/exemplo.py:1 in `<module>`
Extra
O objetivo principal da feature de rastreamento é dar ao usuário a habilidade de encontrar onde a falha aconteceu, mas se você não quer analizar a pilha de chamadas e sabe o cenário onde a falha ocorre, use o plugin da returns para pytest para verificar sua hipótese. Nós disponibilizamos uma fixture chamada returns com o método has_trace, de uma olhada no exemplo abaixo:
from returns.result import Result, Success, Failure
def funcao_exemplo(arg: str) -> Result[int, str]:
if arg.isnumeric():
return Success(int(arg))
return Failure('"{0}" não é um número'.format(arg))
def test_if_failure_is_created_at_exemplo(returns):
with returns.has_trace(Failure, funcao_exemplo):
Success('não é número').bind(funcao_exemplo)
Se test_if_failure_is_created_at_exemplo falhar nós sabemos que a falha não foi
criada na funcao_exemplo ou em alguma de suas chamadas internas.